
Data Mesh — A Data Movement and Processing Platform @ Netflix
By Bo Lei, Guilherme Pires, James Shao, Kasturi Chatterjee, Sujay Jain, Vlad Sydorenko
Background
Realtime processing technologies (A.K.A stream processing) is one of the key factors that enable Netflix to maintain its leading position in the competition of entertaining our users. Our previous generation of streaming pipeline solution Keystone has a proven track record of serving multiple of our key merchantry needs. However, as we expand our offerings and try out new ideas, there’s a growing need to unlock other emerging use cases that were not yet covered by Keystone. After evaluating the options, the team has decided to create Data Mesh as our next generation data pipeline solution.
Last year we wrote a blog post well-nigh how Data Mesh helped our Studio team enable data movement use cases. A year has passed, Data Mesh has reached its first major milestone and its telescopic keeps increasing. As a growing number of use cases on workbench to it, we have a lot increasingly to share. We will unhook a series of wares that imbricate variegated aspects of Data Mesh and what we have learned from our journey. This vendible gives an overview of the system. The pursuit ones will swoop deeper into variegated aspects of it.
Data Mesh Overview
A New Definition Of Data Mesh
Previously, we specified Data Mesh as a fully managed, streaming data pipeline product used for enabling Change Data Capture (CDC) use cases. As the system evolves to solve increasingly and increasingly use cases, we have expanded its telescopic to handle not only the CDC use cases but moreover increasingly unstipulated data movement and processing use cases such that:
- Events can be sourced from increasingly generic applications (not only databases).
- The itemize of misogynist DB connectors is growing (CockroachDB, Cassandra for example)
- More Processing patterns such as filter, projection, union, join, etc.
As a result, today we pinpoint Data Mesh as a unstipulated purpose data movement and processing platform for moving data between Netflix systems at scale.
Overall Architecture
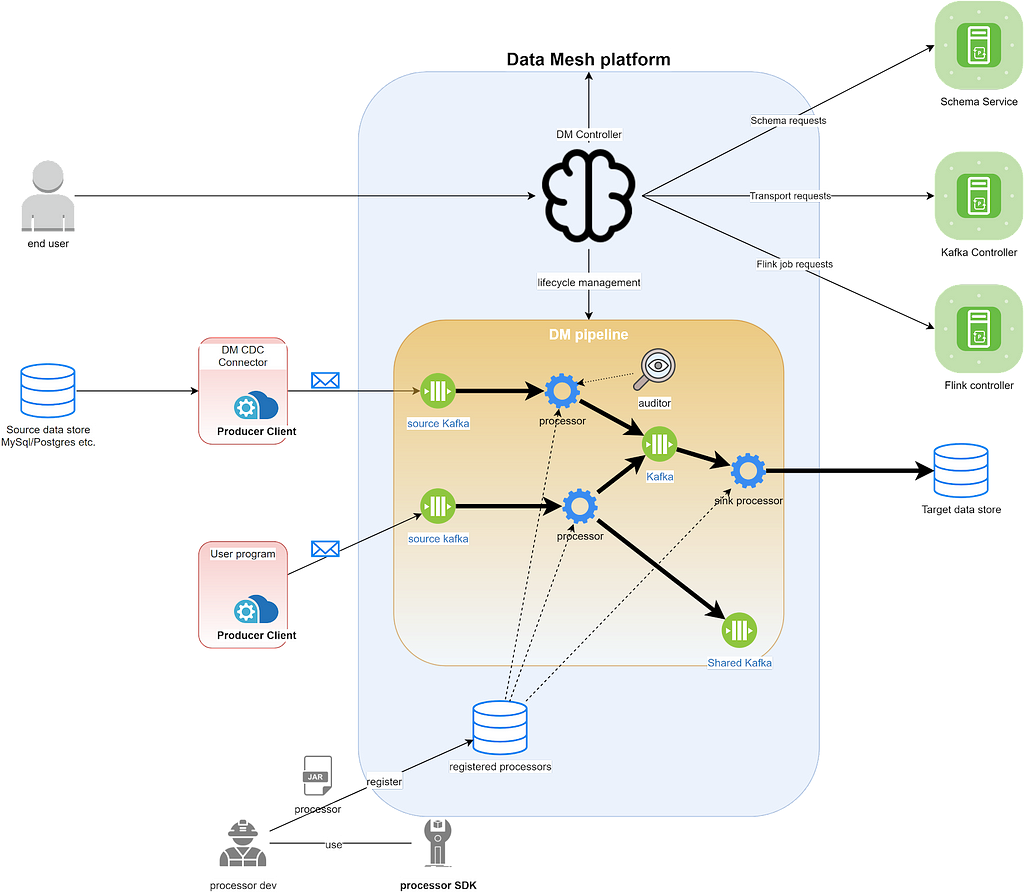
The Data Mesh system can be divided into the tenancy plane (Data Mesh Controller) and the data plane (Data Mesh Pipeline). The controller receives user requests, deploys and orchestrates pipelines. Once deployed, the pipeline performs the very heavy lifting data processing work. Provisioning a pipeline involves variegated resources. The controller delegates the responsibility to the respective microservices to manage their life cycle.
Pipelines

A Data Mesh pipeline reads data from various sources, applies transformations on the incoming events and sooner sinks them into the destination data store. A pipeline can be created from the UI or via our declarative API. On the creation/update request the controller figures out the resources associated with the pipeline and calculates the proper configuration for each of them.
Connectors
A source connector is a Data Mesh managed producer. It monitors the source database’s bin log and produces CDC events to the Data Mesh source fronting Kafka topic. It is worldly-wise to talk to the Data Mesh controller to automatically create/update the sources.
Previously we only had RDS source connectors to listen to MySQL and Postgres using the DBLog library; Now we have widow Cockroach DB source connectors and Cassandra source connectors. They use variegated mechanisms to stream events out of the source databases. We’ll have blog posts deep swoop into them.
In wing to managed connectors, using owners can emit events via a worldwide library, which can be used in circumstances where a DB connector is not yet misogynist or there is a preference to emit domain events without coupling with a DB schema.
Sources
Application developers can expose their domain data in a internal itemize of Sources. This allows data sharing as multiple teams at Netflix may be interested in receiving changes for an entity. In addition, a Source can be specified as a result of a series of processing steps — for example an enriched Movie entity with several dimensions (such as the list of Talents) that remoter can be indexed to fulfill search use cases.
Processors
A processor is a Flink Job. It contains a reusable unit of data processing logic. It reads events from the upstream transports and applies some merchantry logic to each of them. An intermediate processor writes data to flipside transport. A sink processor writes data to an external system such as Iceberg, ElasticSearch, or a separate discoverable Kafka topic.
We have provided a Processor SDK to help the wide users to develop their own processors. Processors ripened by Netflix developers outside our team can moreover be registered to the platform and work with other processors in a pipeline. Once a processor is registered, the platform moreover automatically sets up a default zestful UI and metrics dashboard
Transports
We use Kafka as the transportation layer for the interconnected processors to communicate. The output events of the upstream processor are written to a Kafka topic, and the downstream processors read their input events from there.
Kafka topics can moreover be shared wideness pipelines. A topic in pipeline #1 that holds the output of its upstream processor can be used as the source in pipeline #2. We commonly see use cases where some intermediate output data is needed by variegated consumers. This diamond enables us to reuse and share data as much as possible. We have moreover implemented the features to track the data lineage so that our users can have a largest picture of the overall data usage.
Schema
Data Mesh enforces schema on all the pipelines, meaning we require all the events passing through the pipelines to conform to a predefined template. We’re using Avro as a shared format for all our schemas, as it’s simple, powerful, and widely unexplored by the community..
We make schema as the first matriculation resider in Data Mesh due to the pursuit reasons:
- Better data quality: Only events that comply with the schema can be encoded. Gives the consumer increasingly confidence.
- Finer granularity of data lineage: The platform is worldly-wise to track how fields are consumed by variegated consumers and surface it on the UI.
- Data discovery: Schema describes data sets and enables the users to scan variegated data sets and find the dataset of interest.
On pipeline creation, each processor in that pipeline needs to pinpoint what schema it consumes and produces. The platform handles the schema validation and compatibility check. We have moreover built automation virtually handling schema evolution. If the schema is reverted at the source, the platform tries to upgrade the consuming pipelines automatically without human intervention.
Future
Data Mesh Initially started as a project to solve our Change Data Capture needs. Over the past year, we have observed an increasing demand for all sorts of needs in other domains such as Machine Learning, Logging, etc. Today, Data Mesh is still in its early stage and there are just so many interesting problems yet to be solved. Below are the highlights of some of the upper priority tasks on our roadmap.
Making Data Mesh The Paved Path (Recommended Solution) For Data Movement And Processing
As mentioned above, Data Mesh is meant to be the next generation of Netflix’s real-time data pipeline solution. As of now, we still have several specialized internal systems serving their own use cases. To streamline the offering, it makes sense to gradually migrate those use cases onto Data Mesh. We are currently working nonflexible to make sure that Data Mesh can unzip full-length parity to Delta and Keystone. In addition, we moreover want to add support for increasingly sources and sinks to unlock a wide range of data integration use cases.
More Processing Patterns And Largest Efficiency
People use Data Mesh not only to move data. They often moreover want to process or transform their data withal the way. Flipside upper priority task for us is to make increasingly worldwide processing patterns misogynist to our users. Since by default a processor is a Flink job, having each simple processor doing their work in their own Flink jobs can be less efficient. We are moreover exploring ways to merge multiple processing patterns into one single Flink job.
Broader support for Connectors
We are commonly asked by our users if Data Mesh is worldly-wise to get data out of datastore X and land it into datastore Y. Today we support unrepealable sources and sinks but it’s far from enough. The demand for increasingly types of connectors is just enormous and we see a big opportunity superiority of us and that’s definitely something we moreover want to invest on.
Data Mesh is a ramified yet powerful system. We believe that as it gains its maturity, it will be instrumental in Netflix’s future success. Again, we are still at the whence of our journey and we are excited well-nigh the upcoming opportunities. In the pursuit months, we’ll publish increasingly wares discussing variegated aspects of Data Mesh. Please stay tuned!
The Team
Data Mesh wouldn’t be possible without the nonflexible work and unconfined contributions from the team. Special thanks should go to our stunning colleagues:
Bronwyn Dunn, Jordan Hunt, Kevin Zhu, Pradeep Kumar Vikraman, Santosh Kalidindi, Satyajit Thadeshwar, Tom Lee, Wei Liu
Data Mesh — A Data Movement and Processing Platform @ Netflix was originally published in Netflix TechBlog on Medium, where people are standing the conversation by highlighting and responding to this story.










